Month: February 2020
-
Monthly notes 48
This time monthly notes is for learning Node.js best practices and some interesting approaches for (Node.js) software architecture. Happy reading and be a better developer! Issue 48, 25.2.2020 Learning Docker and Node.js Best Practices talk at DockerCon 2019Slides and Examples . tl;dr; Use even numbered LTS releases; Don’t use :latest tag; Use Debian:slim/stretch or Alpine;…
-
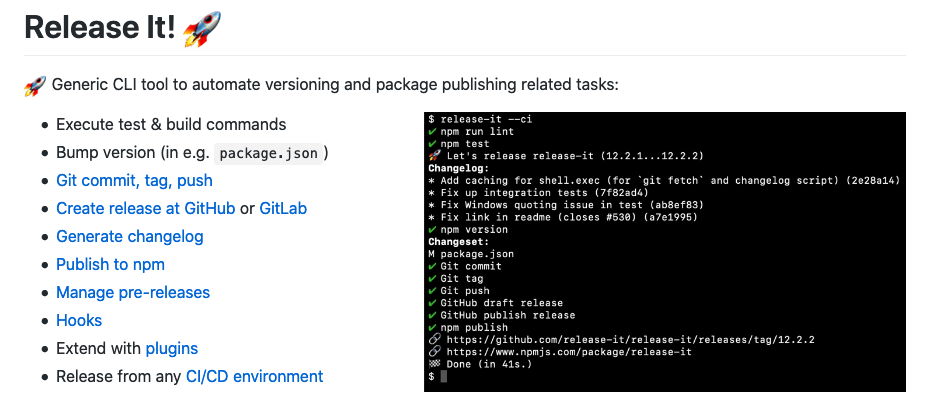
Automate versioning and changelog with release-it on GitLab CI/CD
It’s said that you should automate all the things and one of the things could be versioning your software. Incrementing the version number in your e.g. package.json is easy but it’s easier when you bundle it to your continuous integration and continuous deployment process. There are different tools you can use to achieve your needs…
-

Reset Hasura migrations and squash files
Using GraphQL for creating REST APIs is nowadays popular and there are different tools you can use. One of them is Hasura which is an open-source engine that gives you realtime GraphQL APIs on new or existing Postgres databases. Hasura is quite easy to work with but if your GraphQL schemas change a lot it creates…