This year has been challenging for meetups and gatherings but one good side of the restrictions was that remote work has become more acceptable and also meetups and conferences have invested to streaming and virtual participation which is great for people living in an area where there’s no meetups.
In early May HelSec kept their first Virtual Meetup with great topics. Here’s my short notes (finally four months later). The meetup was streamed via HelSec Twitch channel and the discussions were in HelSec Events Discord. The meetup recording is available from Twitch.

HelSec Virtual Meetup #1 (7.5.2020)
Fighting alert fatigue and visibility issues in SOC
Juuso Myllylä from OptimeSys talked about fighting alert fatigue in security operations center (stream from 41:41 onwards). The goal in the talk was to improve automated detection, introduce “detection logic killchain” framework he has worked on as his master’s thesis and shift our minds from signature based detection and move towards intelligence based.
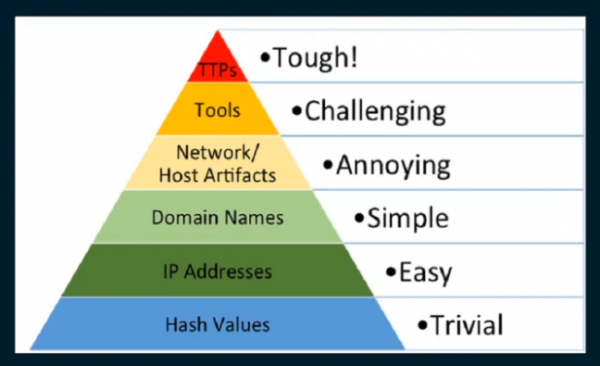
Threat detection framework based on design science research method:
- Identify: What is a threat? What kind of things make up a threat?
- Mitre’s ATT&CK framework
- Mitre’s ATT&CK: Design and philosophy
- Example: hijacked Azure AD account detection
- Tactic = initial access
- Detect: How we can detect a threat?
- Logs, logs, logs
- Technique detection is also valid
- Example technique: valid accounts or phishing
- Use Case: Search queries, log sources, etc.
- Convert your idea into a security information and event management (SIEM) search query
- Procedures: many APT (Advanced Persistent Threat) groups have used valid accounts as an entrypoint
- Demonstrate:
- Deploy the use case
- Evaluate: evaluate detection logic
- Analyze the SIEM logs once your SIEM use case has been deployed
- e.g. check Azure AD audit logs, eliminate non-related data
- Applies also to threat hunting
- Communicate: Document your detection logic in Sigma form
- Can be shared with others, try to be SIEM agnostic
iPhone BFU Acquisition and Analysis
The meetup continued with iPhone forensic from @1:19 by Timo Miettinen from Nixu. The presentation explained first how the iPhone iOS filesystem’s two main partitions are protected: non-encrypted System and encrypted Data. Data partition is encrypted with burned-into-hardware UID key. The files have additionally 4 classes of Data Protection.
From forensics point of view access to data is protected with many layers: USB connectivity is restricted; Logical extraction is divided to iTunes backup + some media files, password protected backups contain more data, backup password can be reset but has deviations; Full file system extraction needs jailbraking the device; iCloud extraction (synced backup).
The case talked in the talk was a lost iPhone which was later returned by law enforcement. The question was: What was done with it while missing? Was it stolen or just inspected by friendly authorities? Phone was powered off and passcode was changed.
So they had BFU device in their hands for data extraction: device that has been powered off or rebooted and has never been subsequently unlocked. The amount of the data they can theoretically get is really limited.
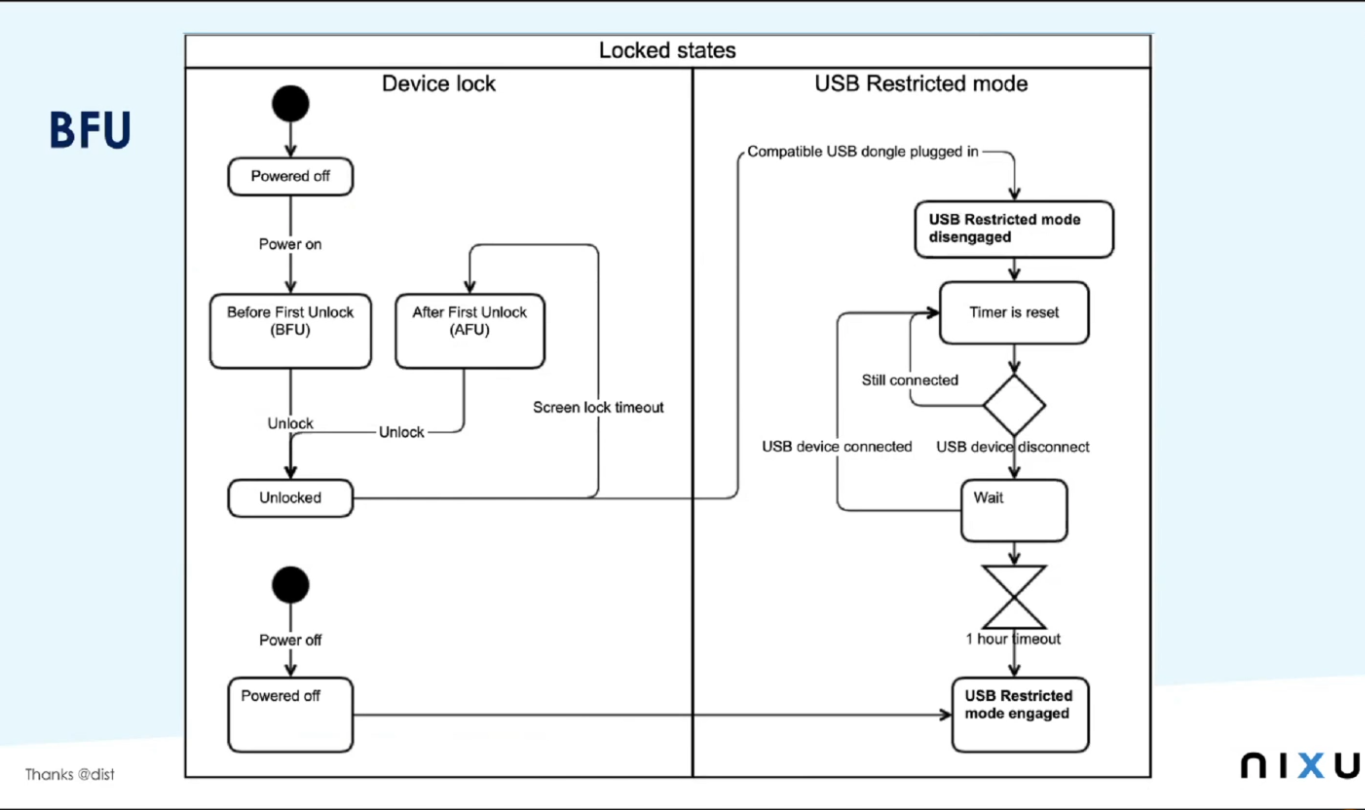
BFU : before first unlock.
In BFU the file encryption keys are wiped from the device RAM and only unencrypted class D protected files are available. Biometric authentication is not possible, USB restricted mode is enabled (need biometric authentication or passcode to activate data connections), lockdown records become useless (logical data acquisition impossible) and passcode recovery attack falls to BFU speeds.
Acquisition methods:
- Utilizing exploits and jailbreaks:
- checkm8: unpatchable bootrom exploit released by axi0mx on September 2019 which enables jailbreaks, activation lock bypass etc.
- checkra1n: jailbreak released on November 2019 which utilizes the checkm8 exploit to run unsigned code on an iOS device. Doesn’t always pass the USB restricted mode, depends on the combinations of hardware and software versions.
- Open source and free tools:
- libimobiledevices has collection of useful tools:
- SSH over USB using iproxy
- ideviceinfo gives iOS and HW versions
- idevicecrashreport gets crash logs from the device
- many more
- ios_bfu_triage: extract avaible data
- iTUnes if you don’t have the BFU restriction
- libimobiledevices has collection of useful tools:
- Commercial tools: Belkasoft Evidence Center, BlackBag Mobilyze, Cellebrite UFED / Physical Analyzer, Elcomsoft Phone Viewer, Magnet AXIOM, MSAB XRY, Oxygen Forensics Extractor
In their use case the checkra1n jailbreak didn’t work and USB restricted mode was activated. Also some of the commercial tools enabled to extract some data but wasn’t able to read the archive format the software created. They decided to the analysis manually which is a good idea even if the tools are working.
Some open source or free tools for analysis:
- APOLLO (Apple Pattern of Life Lazy Output’er): parses pattern of life data from databases and properties into human readable format.
- iOS sysdiagnose forensic scripts: parses iOS sysdiagnose logs.
- iPhone Backup Analyzer: allows the user to browse the content of an iOS backup.
- iLEAPP (iOS Logs, Events, And Preferences Parser)
- iBackup Viewer: browse the content of an iOS backup and extract files.
- ftree: crawl any directory and identify all files etc.
- deserializer: converts from NSKeyedArchive to normal plist
- For reading plists you can use: plutil -p <filename>
- DB Browser for SQLite
- Google’s protobuf utilities (protoc)
When doing analysis you should look for plists, binary plists, plists in plists, blobs may contain binary plist files and SQLite databases (Shared Memory file .shm, write ahead log .wal). Some applications store data in protocol buffers (protobufs) in SQLite database blobs, plist files or just data files. Tools find most of the interesting data but you can make your own script to dump all text files, convert plist files to readable format, dumps data from every database, get all embedded binary plists from plist files and databases and convert them to readable format.
In their case they found out that the phone was reinstalled 12 hours after it was lost. Mobile banking, social media and instant messaging applications were installed. The device was used to communicate with several contacts and used around the city. The phone was stolen and reinstalled with intention to use it.
Still Fuzzing Faster (U Fool)
Joona Hoikkala talked about Web Fuzzing and using fuff tool for fuzzing directories, login, basic auth, virtual domain, content id:s and more. Follow the talk from the stream at 2:19:00 and the demo starts around @2:33:00. The slides are good starting point.

You can use fuzzing with different input contents to target i.a. GET parameters (names, values or both), headers (Host, authentication, cookies, proxy headers) and POST data (form data, JSON, files). What to look for (matching)? Response codes, content (regexes) response sizes (bytes, # of words).
Resources: SecLists
Price of a digital identity
Laura Kankaala, from Robocorp and Team Whack fame talked about the price of a digital identity starting at 3:20:40. Data is central, security – privacy: how companies view data and how data sellers view data.
Digital identity:
- What we are
- What we have
- What we produce
Laura also presented that ~90-99% of data collected is dark data which is collected but not really utilized. But we are just getting started. But it’s good to remember that our data belongs to us. We give permission to collectors and controllers.
Do you know what’s your data worth? Data is valuable and for example there are companies like doc.ai and datum which tries to monetize it so that also user gets part of it. But yet the data is used more for targeted ads, providing content just for us, increasing efficiency and creating better services. And of course every one remembers Cambridge Analytica and (trying) to affect electoral processes in the US.
The most valuable things being sold online are: credit cards, identity numbers, passports, credentials, phone numbers, home address. Passports are quite logical of value and e.g. France passport goes for $124, USA $115, Canada $103, UK $60 and so on, depending of the data included with it.
Kankaala talked about how the collecting of our data has sneak to our lives (e.g. social credit systems). Companies collect data and when our normal live becomes very tangled with our live online it becomes easier to monitor us, to see what we’re up to and to moderate our behaviour. We need to be careful when we allow new type of access to our live, e.g. COVID-19 tracking.
Regulation, awareness and education is at least a patch to some of these issues. We are hackers and we should be the pathfinders and show people that it doesn’t have to be that if something works the way it does today and although it works it doesn’t mean it works right or ethically.
We are all vulnerable
Magnus Lundgren from Recorded Future told a tale of two databases, a panda and someone who was listening starting at 4:25:00.
There’s a race of when vulnerability is found and assigned a CVE number until it’s either patched or exploited. 12 517 CVEs were first published on NVD in 2016-2017 and it takes average 33 days until an initial assesment of the vulnerability is made available via NIST’s NVD. For example Dirty Cow (CVE-2016-519) it took 21 days to initial release on NVD but it took only 8 days to create an exploit (Proof of Concept shared on Pastebin) for it and sold/shared on the deep and dark web.
A tale of two databases: NVD (NIST) and CNNVD (CNITSEC). In the Chinese CNNVD it takes on average only 13 days compared to 33 days on NVD for initial assesment. The difference comes from the detail that CNNCD is doing active collection while NVD is doing passive collection from vendors. But always it doesn’t be that way like it was the case with some Android backdoor where it took 236 days from CNNVD and 60 days from NVD. It takes longer for CNNVD to publish high threat vulnerabilities than low threat ones and during the publication lag Chinese APT groups are exploiting those vulnerabilities.
When the Recorded Future published a blog post identifying 343 “outlier” CVEs (regarding the issue the of CNNVD lag) CNNVD backdated 338 of those CVEs. Someone was listening.
Conclusions:
- Deep / Dark web monitoring of activity is crucial for a good patching cadence.
- Magic can be done with threat intel data that has been organiced for analysis.
- Chinese intersection is particularly vicious for foreign companies: Ministry of State Security (China) runs multiple threat actors e.g. APT3, runs CNNVD and cherry picks CNNVD vulnerabilities for targeting.
Resources: Inside Security Intelligence podcast
Leave a Reply