Category: Meetups
-

First ever SaimaaSec event at LUT
The first ever SaimaaSec meetup was organized last week and had three presentations from the infosec and cybersecurity industry. The event was held at LUT University which also sponsored it. Here are my (very) short notes from the presentations. War stories from Incident Response – key takeaways Juho Jauhiainen talked about incident responses and war…
-

Notes from HelSec Virtual Meetup 1
This year has been challenging for meetups and gatherings but one good side of the restrictions was that remote work has become more acceptable and also meetups and conferences have invested to streaming and virtual participation which is great for people living in an area where there’s no meetups. In early May HelSec kept their…
-

Notes from DEVOPS 2020 Online conference
DevOps 2020 Online was held 21.4. and 22.4.2020 and the first day talked about Cloud & Transformation and the second was 5G DevOps Seminar. Here are some quick notes from the talks I found the most interesting. The talk recordings are available from the conference site. DevOps 2020 How to improve your DevOps capability in…
-
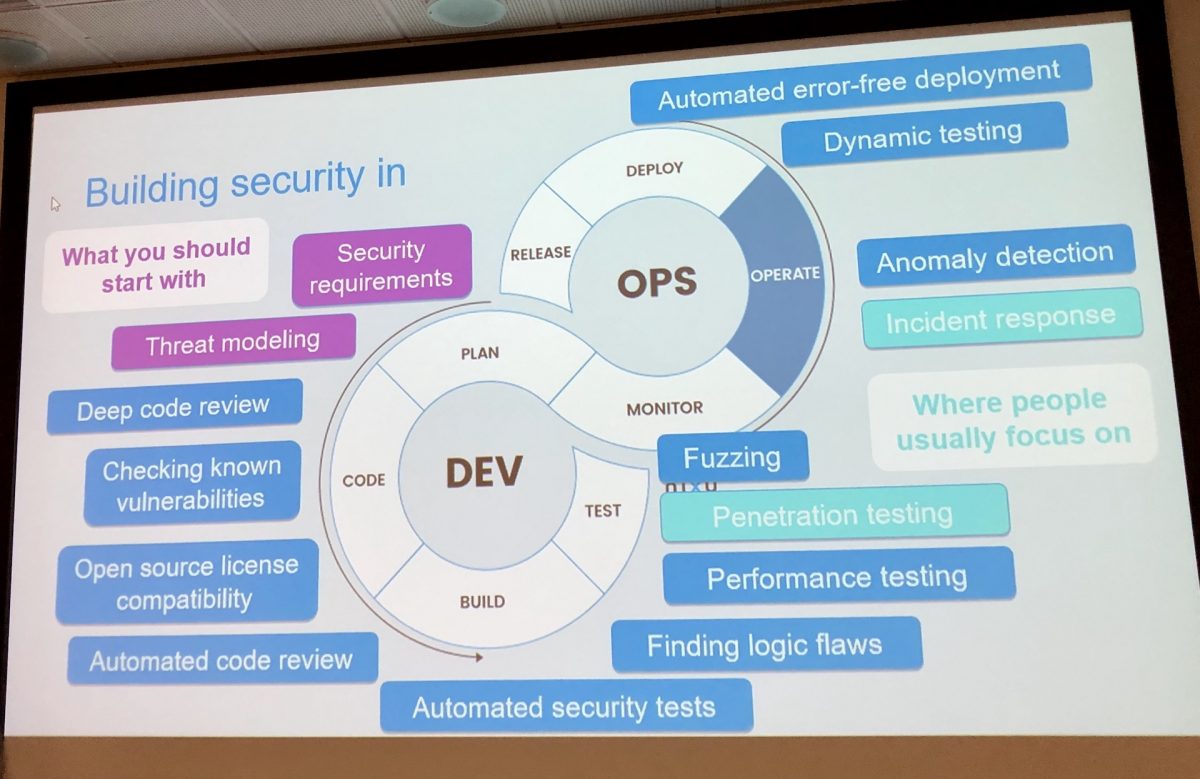
Notes from OWASP Helsinki chapter meeting 36
OWASP Helsinki chapter meeting number 36 was held 12.2.2019 at Veikkaus premises in Pohjois-Haaga. The theme for this meeting was about software security and the topic was covered with two talks and with a card game. Here’s my short notes. What Every Developer and Tester Should Know About Software Security The event started with “What Every…
-
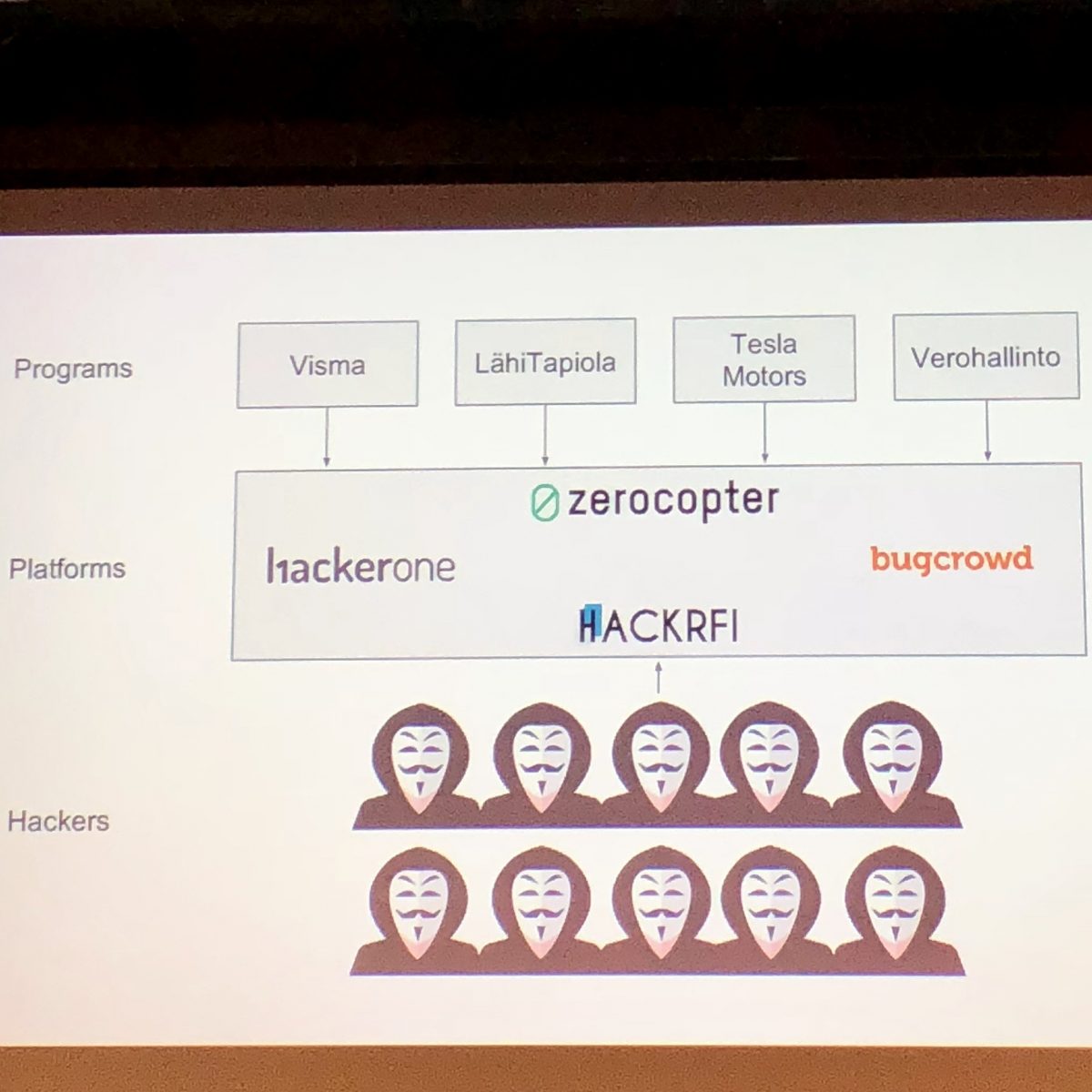
Notes from OWASP Helsinki chapter meeting 35: Bug Bounty programs
Have you ever wondered how to become a bug bounty hunter or wanted to organize a bug bounty program? OWASP Helsinki chapter meeting number 35 told all about bug bounty programs from hacker and organizer point of views. The event was held 6.11.2018 at Second Nature Security (2NS) premises in Keilaniemi.… Jatka lukemista →
-

Notes from GraphQL Finland 2018
GraphQL Finland 2018 conference was held last week (18-19.10.2018) at Paasitorni and the first of its kind event in Finland brought a day of workshops and a day of talks around GraphQL. The event was organized by the same people as React Finland and it showed, in good ways. The talks were interesting, venue was…
-

Notes from Red Hat Forum Finland 2018: Ideas worth exploring
Red Hat Forum Finland 2018 was held 11.9.2018 at Finlandia-talo and it’s mainline was “Ideas worth exploring. Come with questions. Leave with ideas.” The event was divided to keynote and to four breakout sessions. The four breakout sessions were: 1. Automation – Ansible 2. Journey to Cloud-Native Applications with OpenShift 3.… Jatka lukemista →
-
Notes from React Helsinki August 2018 meetup
React Helsinki August 2018 meetup was hosted by Smartly.io at their office in Postitalo next to the Central Railway Station. Here’s my short notes from the event. To follow the community, React Helsinki has also a Facebook group. The meetup started with Splitting React codebases for increased development speed by Hugo Kiiski from Smartly.io.… Jatka…
-

OWASP Helsinki chapter meeting 34: Secure API
OWASP Helsinki Chapter held a meeting number 34 last week at Eficode with topics of “Perfectly secure API” and “Best friends: API security & API management”. The event gave good overview to the topics covered and was quite packed with people. Eficode’s premises were modern and there was snacks and beverages.… Jatka lukemista →
-

Two days of React Finland 2018: Day two with React and React Native
React Finland 2018 conference was held last week and I had the opportunity to attend it and listen what’s hot in the React world. The conference started with workshops and after that there was two days of talks of React, React Native, React VR and all things that go with developing web applications with them.……