Tag: Programming
-

Jailbreak detection with jail-monkey on React Native app
Mobile device operating systems often impose certain restrictions to what capabilities the user have on the device like which apps can be installed on the device and what access to information and data apps and user have on the device. The limitations can be bypassed with jailbreaking or rooting the device which might introduce security…
-
Override nested NPM dependency versions
Sometimes your JavaScript project’s dependency contains a library which has a vulnerability and you’re left with a question how to solve the issue. If the nested dependency (with vulnerability) is already fixed but the main dependency isn’t, you can use overrides field of package.json as explained in StackOverflow answer. You’ll need a recently new version…
-
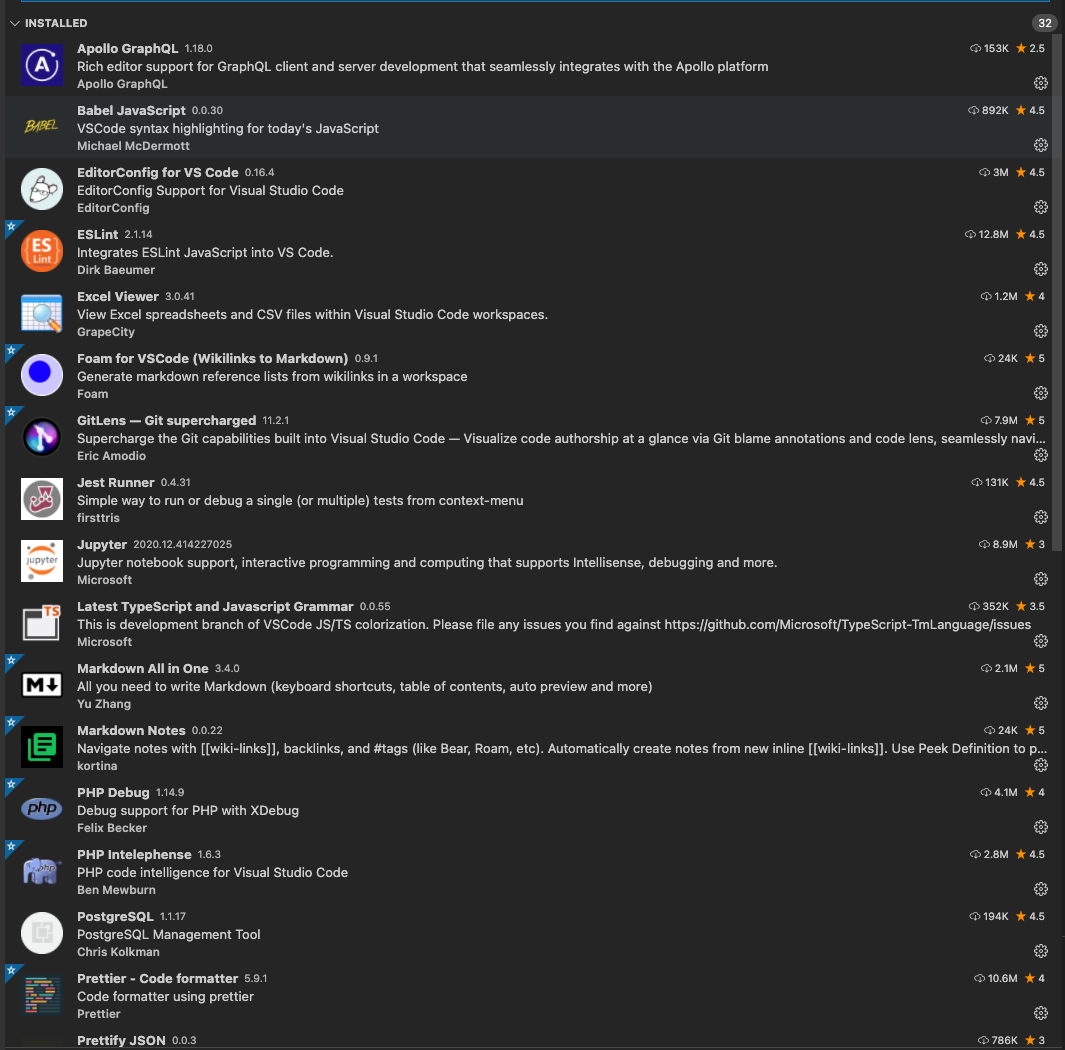
Visual Studio Code Extensions for better programming
Visual Studio Code has become “The Editor” for many in software development and it has many extensions which you can use to extend the functionality for your needs and customize it. Here’s a short list of the extensions I use for frontend (React, JavaScript, Node.js), backend (GraphQL, Python, Node.js, Java, PHP, Docker) and database (PostgreSQL,…
-
Keep Maven dependencies up to date
Software development projects come usually with lots of dependencies and keeping them up to date can be burdensome if done manually. Fortunately there are tools to help you. For Node.js projects there are e.g. npm-check and npm-check-updates and for Maven projects there are OWASP/Dependency-Check and Versions Maven plugins. Here’s a short introduction how to setup…
-
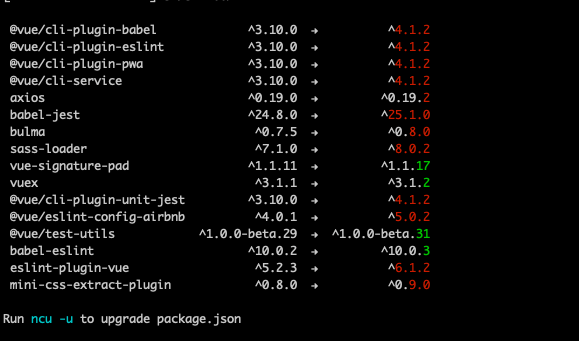
Tracking vulnerabilities and keeping Node.js packages up to date
Software evolves quickly and new versions of libraries are released but how do you keep track of updated dependencies and vulnerable libraries? Managing dependencies has always been somewhat a pain point but an important part of software development as it’s better to be tracking vulnerabilities and running fresh packages than being pwned.… Jatka lukemista →
-
Automate validating code changes with Git hooks
What could be more annoying than committing code changes to repository and noticing afterwards that formatting isn’t right or tests are failing? Your automated tests on Continuous Integration shows rain clouds and you need to get back to the code and fix minor issues with extra commits polluting the git history?… Jatka lukemista →
-

Best Practices of forking git repository and continuing development
Sometimes there’s a need to fork a git repository and continue development with your own additions. It’s recommended to make pull request to upstream so that everyone could benefit of your changes but in some situations it’s not possible or feasible. When continuing development in forked repo there’s some questions which come to mind when…
-
Expanding your horizons on JVM with Kotlin
The power of Java ecosystem lies in the Java Virtual Machine (JVM) which runs variety of programming languages which are better suitable for some tasks than Java. One relatively new JVM language is Kotlin which is statically typed programming language that targets the JVM and JavaScript. You can use it with Java, Android and the…
-
Patching RichFaces 3.3.3 AJAX.js for IE11
Couple of years ago I wrote about patching RichFaces 3.3.3 AJAX.js for IE9 and as the browser world has moved on, it’s now time to patch RichFaces 3.3.3 AJAX.js for Internet Explorer 11. Of course you could update your web application to JSF 2 and RichFaces 4 or PrimeFaces but it’s neither trivial nor free.……
-
Patching RichFaces 3.3.3 AJAX.js for IE9
There are always some problems when working with 3rd party frameworks when the world moves forward but the framework you’re using doesn’t. After JSF 2 was released the RichFaces development moved to 4.x version and they dropped support for the older versions although many users are still using the older versions as it’s not trivial…