Tag: Software
-

Prettifying AWS S3 Bucket public index list
Sometimes it’s useful to have a index listing on a AWS S3 bucket. Here are some solutions to configure it with nice template. If having a public index list on a S3 Bucket is a good idea or not I’m not saying yay or nay. First set the correct Bucket Policy { “Version”: “2012-10-17”, “Statement”:…
-
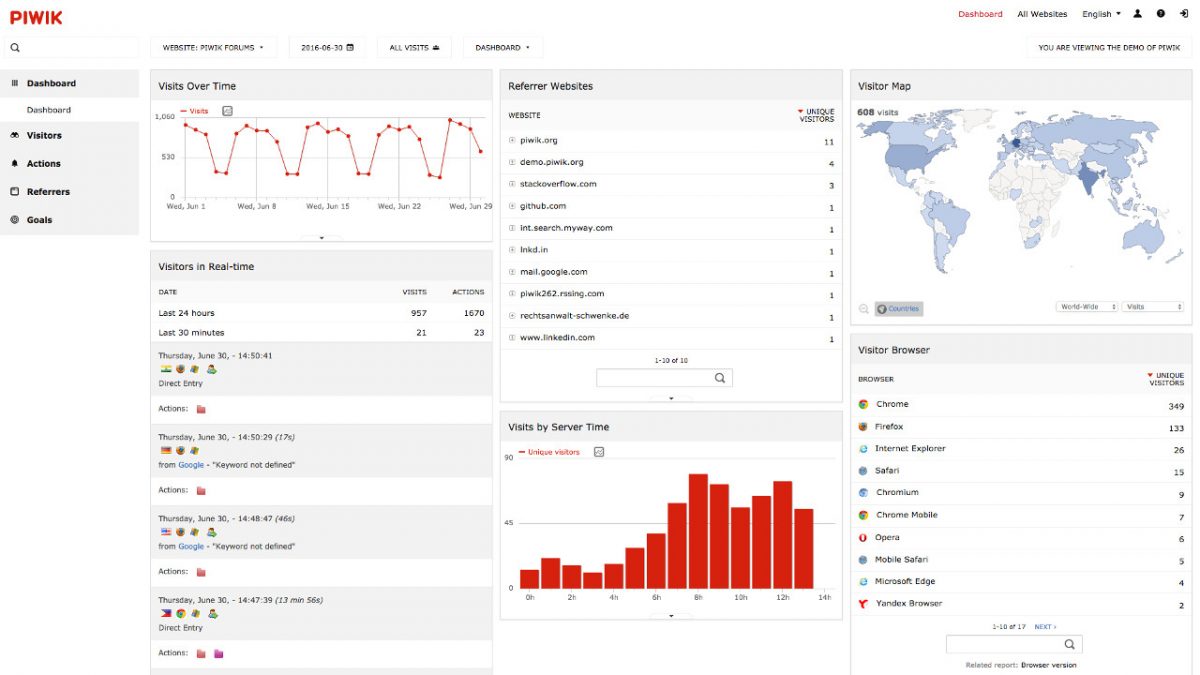
Web analytics with Piwik: keeping control over your own data
Web analytics is one the essential tools for a website and including measuring web traffic and getting information about the number of visitors it can be also used as a tool to assess and improve the effectiveness of a website. The most common way to collect data is to use on-site web analytics, measure a…
-

Starting with WeeChat
I’ve been using IRC for some time and although Irssi has served me well, it’s time to try something different. WeeChat is a modular chat client with support for IRC and the interesting part is that it’s possible to use other interfaces like glowing-bear web frontend. WeeChat is similar to Irssi so switching over shouldn’t…
-

Essential IntelliJ IDEA keyboard shortcuts
Recently I switched from using Eclipse to IntelliJ IDEA as our Java EE application’s front-end was done with JavaScript and the support for front-end technologies in Eclipse is more or less non-existent. The switch for long time Eclipse user wasn’t easy as IDEA works a bit differently but the change was worth it.… Jatka lukemista…
-
Transferring Linux install media to USB thumb drive
Optical drives are nowadays less common on laptops which makes making bootable install medias a little easier. Yes, easier by requiring you to use USB thumb drives. There are different ways to achieve what you want and here is couple of examples how to transfer Linux install media to USB thumb drive on Windows and…
-
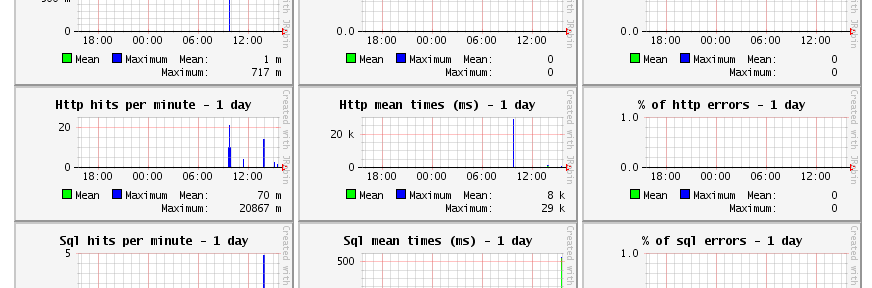
Monitoring Java EE application with JavaMelody
Software development is much more than just coding application by requirements and deploying it to production as the real work really starts after it has been shipped: maintenance, improvements and problem solving. And for that it’s good to have some data. It’s said “if you can’t measure it, you can’t improve it” and in ideal…
-
Eclipse and Maven Console
Eclipse 3.7 Indigo has integrated Maven m2e plugin but is missing some expected functionality which was previously present in Sonatype releases by default. If you want your Maven Console to show something you must also install the optional “m2e – slf4j over logback logging” plugin. When installing the m2e plugin there is an optional feature…