DevOps 2020 Online was held 21.4. and 22.4.2020 and the first day talked about Cloud & Transformation and the second was 5G DevOps Seminar. Here are some quick notes from the talks I found the most interesting. The talk recordings are available from the conference site.

How to improve your DevOps capability in 2020
Marko Klemetti from Eficode presented three actions you can take to improve your DevOps capabilities. It looked at current DevOps trends against organizations on different maturity levels and gave ideas how you can improve tooling, culture and processes.
- Build the production pipeline around your business targets.
- Automation build bridges until you have self-organized teams.
- Adopt a DevOps platform. Aim for self-service.
- Invest in a Design System and testing in natural language:
- brings people in organization together.
- Testing is the common language between stakeholders.
- You can have discussion over the test cases: automated quality assurance from stakeholders.
- Validate business hypothesis in production:
- Enable canary releasing to lower the deployment barrier.
- You cannot improve what you don’t see. Make your pipeline data-driven.
The best practices from elite performers are available for all maturity levels: DevOps for executives.
Practical DevSecOps Using Security Instrumentation
Jeff Williams from Contrast Security talked about how we need a new approach to security that doesn’t slow development or hamper innovation. He shows how you can ensure software security from the “inside out” by leveraging the power of software instrumentation. It establishes a safe and powerful way for development, security, and operations teams to collaborate.

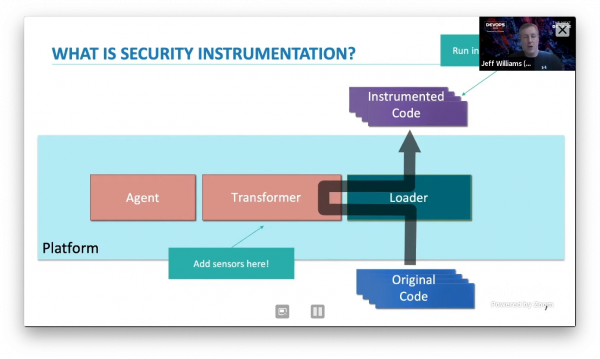
- Security testing with instrumentation:
- Add matchers to catch potentially vulnerable code and report rule violations when it happens, like using unparameterized SQL. Similar what static code analysis does.
- Making security observable with instrumentation:
- Check for e.g. access control for methods
- Preventing exploits with instrumentation:
- Check that command isn’t run outside of scope
The examples were written with Java but the security checks should be implementable also on other platforms.
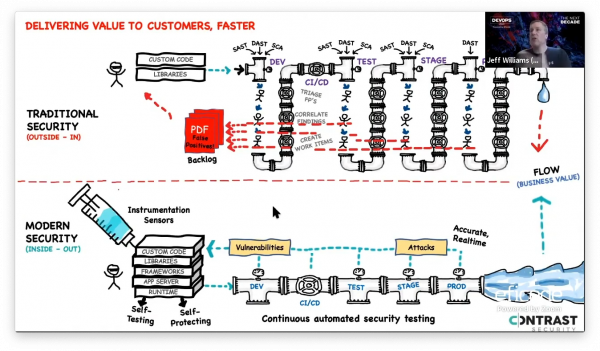
Their AppSec platform’s Community Edition is free to try out but only for Java and .Net.
Open Culture: The key to unlocking DevOps success
Chris Baynham-Hughes from RedHat talked how blockers for DevOps in most organisations are people and process based rather than a lack of tooling. Addressing issues relating to culture and practice are key to breaking down organisational silos, shortening feedback loops and reducing the time to market.

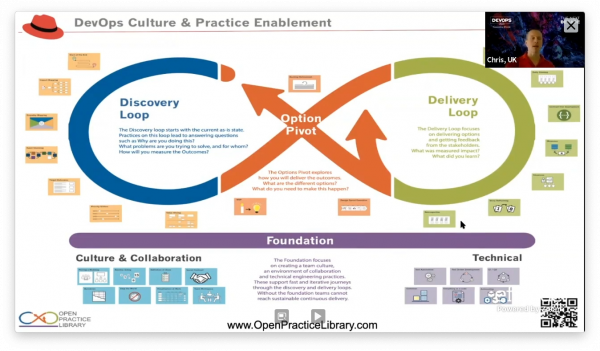
Three layers required for effective transformation:
- Technology
- Process
- People and culture
Scaling DevSecOps to integrate security tooling for 100+ deployments per day
Rasmus Selsmark from Unity talked how Unity integrates security tooling better into the deployment process. Best practices for securing your deployments involve running security scanning tools as early as possible during your CI/CD pipeline, not as an isolated step after service has been deployed to production. The session covered best security practices for securing build and deployment pipeline with examples and tooling.
- Standardized CI/CD pipeline, used to deploy 200+ microservices to Kubernetes.
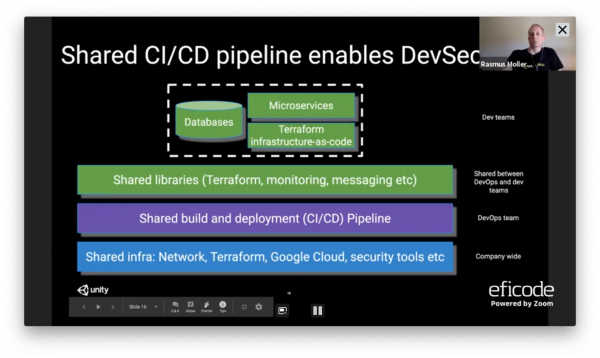
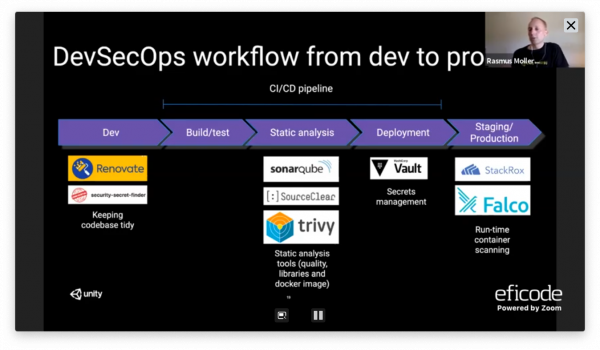
- Dev:
- Keep dependencies updated: Renovate.
- No secrets in code: unity-secretfinder.
- Static analysis
- Sonarqube: Identify quality issues in code.
- SourceClear: Information about vulnerable libraries and license issues.
- trivy: Vulnerability Scanner for Containers.
- Make CI feedback actionable for teams, like generating notifications directly in PRs.
- When to trigger deployment
- PR with at least one approver.
- No direct pushes to master branch.
- Only CI/CD pipeline has staging and production deployment access.
- Deployment
- Secrets management using Vault. Secrets separate from codebase, write-only for devs, only vault-fetcher can read. Values replaced during container startup, no environment variables passed outside to container.
- Production
- Container runtime security with Falco: identify security issues in containers running in production.

Data-driven DevOps: The Key to Improving Speed & Scale
Kohsuke Kawaguchi, Creator of Jenkins, from Launchable talked how some organizations are more successful with DevOps than others and where those differences seem to be made. One is around data (insight) and another is around how they leverage “economy of scale”.
Cost/time trade-off:
- CFO: why do we spend so much on AWS?
- Visibility into cost at project level
- Make developers aware of the trade-off they are making: Build time vs. Annual cost
- Small: 15 mins / $1000; medium: 10 mins / $2000; large: 8 mins / $3000
- Whose problem is it?
- A build failed: Who should be notified first?
- Regular expression pattern matching
- Bayesian filter
- A build failed: Who should be notified first?
Improving software delivery process isn’t get prioritized:
- Data (& story) helps your boss see the problem you see
- Data helps you apply effort to the right place
- Data helps you show the impact of your work
Cut the cost & time of the software delivery process
- Dependency analysis
- Predictive test selection
- You wait 1 hour for CI to clear your pull request?
- Your integration tests only run nightly?

- Reordering tests: Reducing time to first failure (TTFF)
- Creating an adaptive run: Run a subset of your tests?
Deployment risk prediction: Can we flag risky deployments beforehand?
- Learn from previous deployments to train the model
Conclusions
- Automation is table stake
- Using data from automation to drive progress isn’t
- Lots of low hanging fruits there
- Unicorns are using “big data” effectively
- How can the rest of us get there?
Moving 100,000 engineers to DevOps on the public cloud
Sam Guckenheimer from Microsoft talked how Microsoft transformed to using Azure DevOps and GitHub with a globally distributed 24x7x365 service on the public cloud. The session covered organizational and engineering practices in five areas.
Customer Obsession
- Connect our customers directly and measure:
- Direct feedback in product, visible on public site, and captured in backlog
- Develop personal Connection and cadence
- For top customers, have a “Champ” which maintain: Regular personal contact, long-term relationship, understanding customer desires
- Definition of done: live in production, collecting telemetry that examines the hypothesis which motivated the deployment
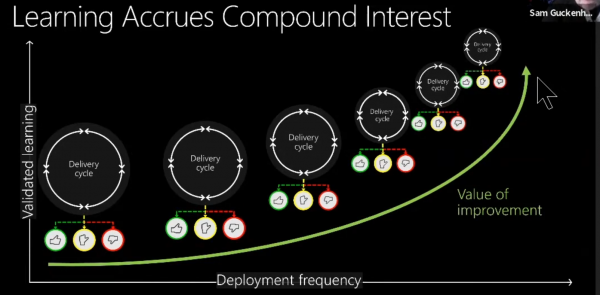
You Build It, You Love It
- Live site incidents
- Communicate externally and internally
- Gather data for repair items & mitigate for customers
- Record every action
- Use repair items to prevent recurrence
- Be transparent
Align outcomes, not outputs
- You get what you measure (don’t measure what you don’t want)
- Customer usage: acquisition, retention, engagement, etc.
- Pipeline throughput: time to build, test, deploy, improve, failed and flaky automation, etc.
- Service reliability: time to detect, communicate, mitigate; which customers affected, SLA per customer, etc.
- “Don’t” measure: original estimate, completed hours, lines of code, burndown, velocity, code coverage, bugs found, etc.
- Good metrics are leading indicators
- Trailing indicators: revenue, work accomplished, bugs found
- Leading indicators: change in monthly growth rate of adoption, change in performance, change in time to learn, change in frequency of incidents
- Measure outcomes not outputs
Get clean, stay clean
- Progress follows a J-curve
- Getting clean is highly manual
- Staying clean requires dependable automation
- Stay clean
- Make technical debt visible on every team’s dashboard
Your aim won’t be perfect: Control the impact radius
- Progressive exposure
- Deploy one ring at a time: canary, data centers with small user counts, highest latency, th rest.
- Feature flags control the access to new work: setting is per user within organization
Shift quality left and right
- Pull requests control code merge to master
- Pre-production test check every CI build
Leave a Reply