Category: DevOps
-
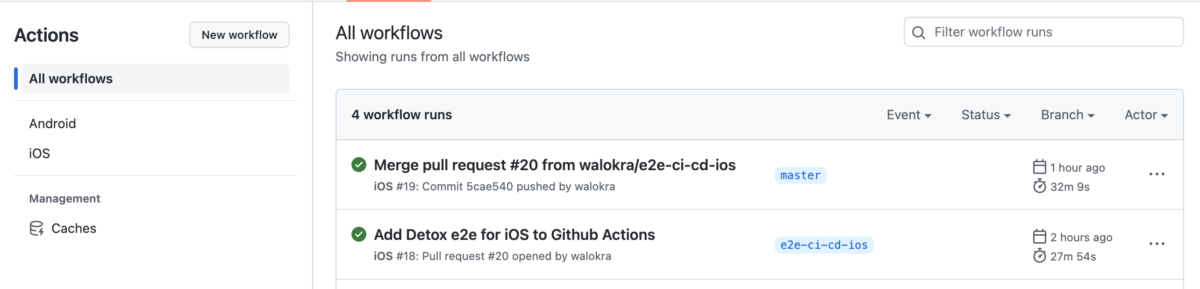
Running Detox end-to-end tests on CI
Now that you’ve added end-to-end tests with Detox to your React Native application from my previous blog post it’s time to automate running the tests and add them to continuous integration (CI) pipeline. Detox has documentation for running it on some Continuous Integration services but it’s somewhat lacking and outdated. This post will show how…
-
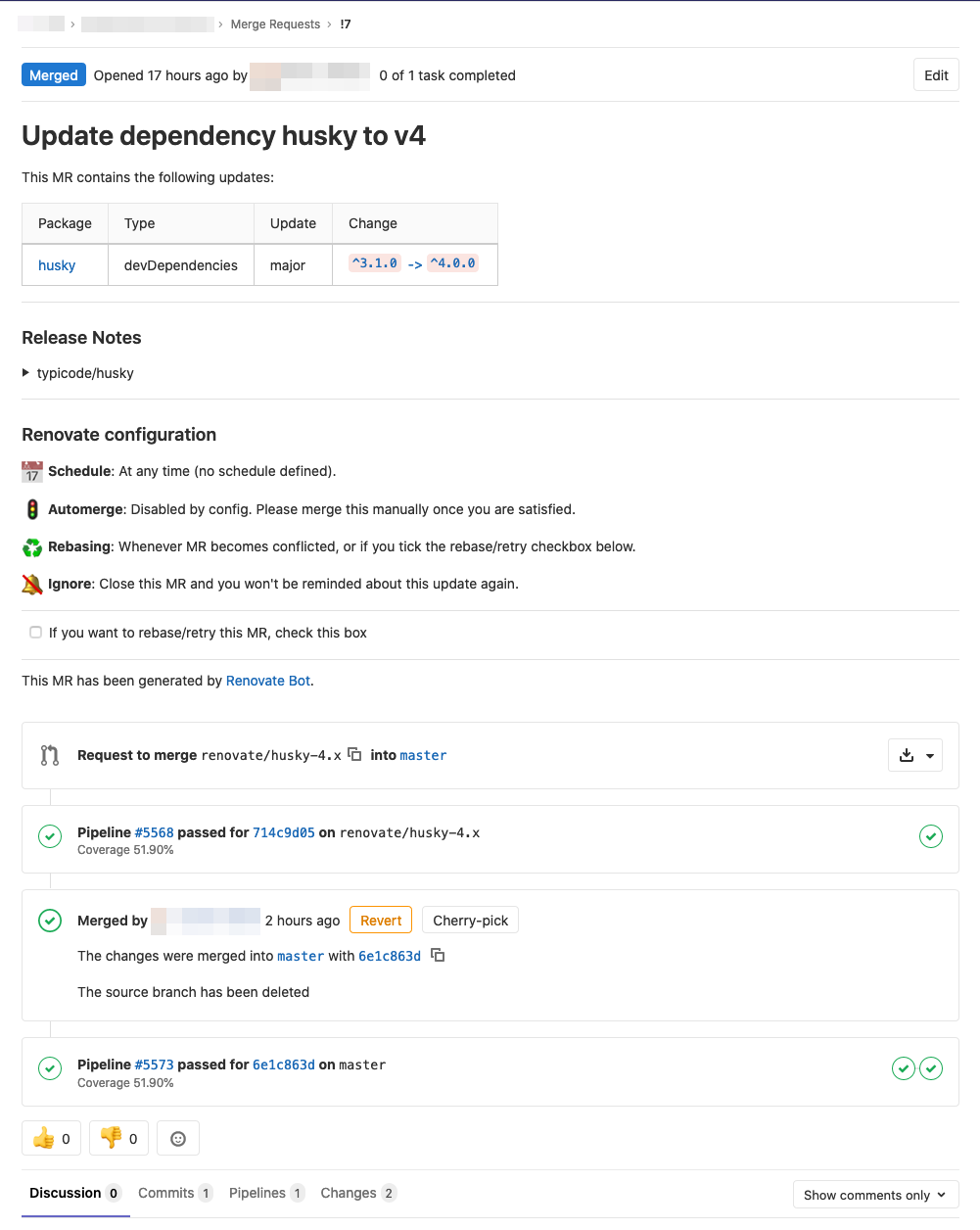
Automate your dependency management using update tool
Software often consists of not just your own code but also is dependent of third party libraries and other software which has their own update cycle and new versions are released now and then with fixes to vulnerabilities and with new features. Now the question is what is your dependency management strategy and how do…
-

Notes from DEVOPS 2020 Online conference
DevOps 2020 Online was held 21.4. and 22.4.2020 and the first day talked about Cloud & Transformation and the second was 5G DevOps Seminar. Here are some quick notes from the talks I found the most interesting. The talk recordings are available from the conference site. DevOps 2020 How to improve your DevOps capability in…
-
Using NGINX Ingress Controller on Google Kubernetes Engine
If you’ve used Kubernetes you might have come across Ingress which manages external access to services in a cluster, typically HTTP. When running with GKE the “default” is GLBC which is a “load balancer controller that manages external loadbalancers configured through the Kubernetes Ingress API”. It’s easy to use but doesn’t let you to to…
-
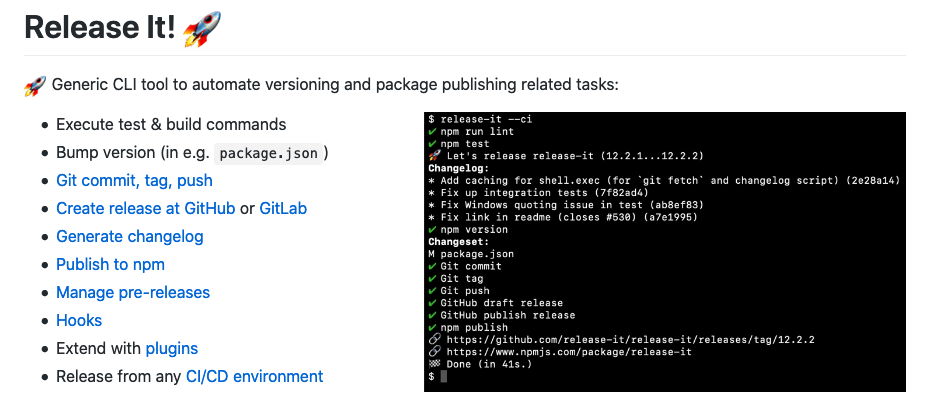
Automate versioning and changelog with release-it on GitLab CI/CD
It’s said that you should automate all the things and one of the things could be versioning your software. Incrementing the version number in your e.g. package.json is easy but it’s easier when you bundle it to your continuous integration and continuous deployment process. There are different tools you can use to achieve your needs…
-

Reset Hasura migrations and squash files
Using GraphQL for creating REST APIs is nowadays popular and there are different tools you can use. One of them is Hasura which is an open-source engine that gives you realtime GraphQL APIs on new or existing Postgres databases. Hasura is quite easy to work with but if your GraphQL schemas change a lot it creates…
-

Notes from security in the age of Docker & Kubernetes
Security is always the more obscure part of software development and while container runtimes provide good isolation from the host operating system when using Docker and running containers in Kubernetes, you should not assume to be free from exploits. Remember to use the best practices when you were not using containers.… Jatka lukemista →
-
Dockerizing all the things: Running Ansible inside Docker container
Automating things in software development is more than useful and using Ansible is one way to automate software provisioning, configuration management, and application deployment. Normally you would install Ansible to your control node just like any other application but an alternate strategy is to deploy Ansible inside a standalone Docker image.… Jatka lukemista →
-

Docker containers and using Alpine Linux for minimal base images
After using Docker for a while, you quickly realize that you spend a lot of time downloading or distributing images. This is not necessarily a bad thing for some but for others that scale their infrastructure are required to store a copy of every image that’s running on each Docker host.… Jatka lukemista →
-

Container orchestration with CoreOS at Devops Finland meetup
Development and Operations, DevOps, is one of the important things when going beyond agile. It’s boosting the agile way of working and can be seen as an incremental way to improve our development practices. And what couldn’t be a good place to improve than learning at meetups how others are doing things.… Jatka lukemista →