Tag: development
-
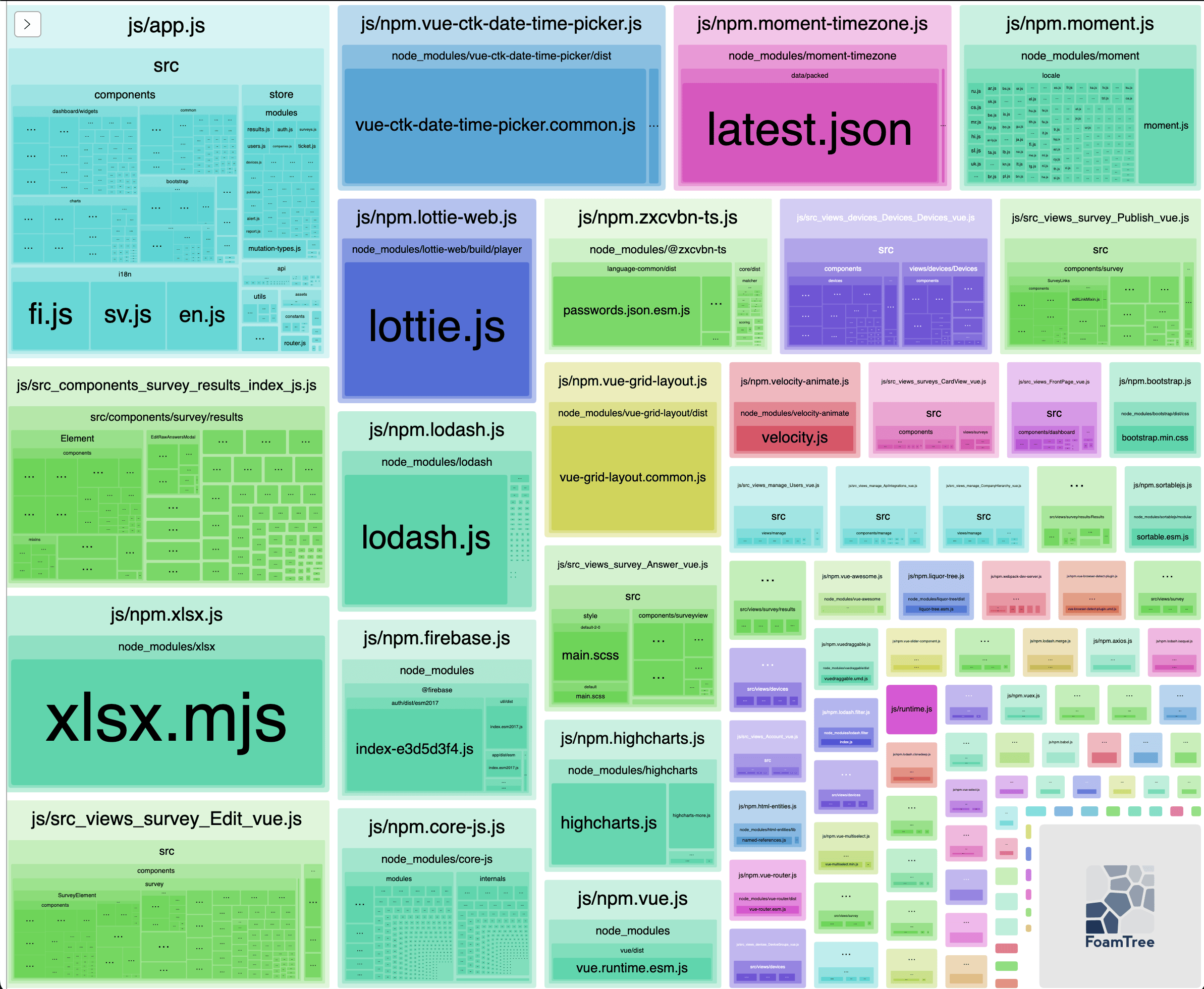
Analyzing Webpack bundles
Packaging your software can be done with different tools which bundles libraries and your code to groups of files (called chunks). Sometimes you might wonder why the chunks are so big and why some libraries are included although they are not used in some view (code splitting). There are different tools to analyze and visualize…
-
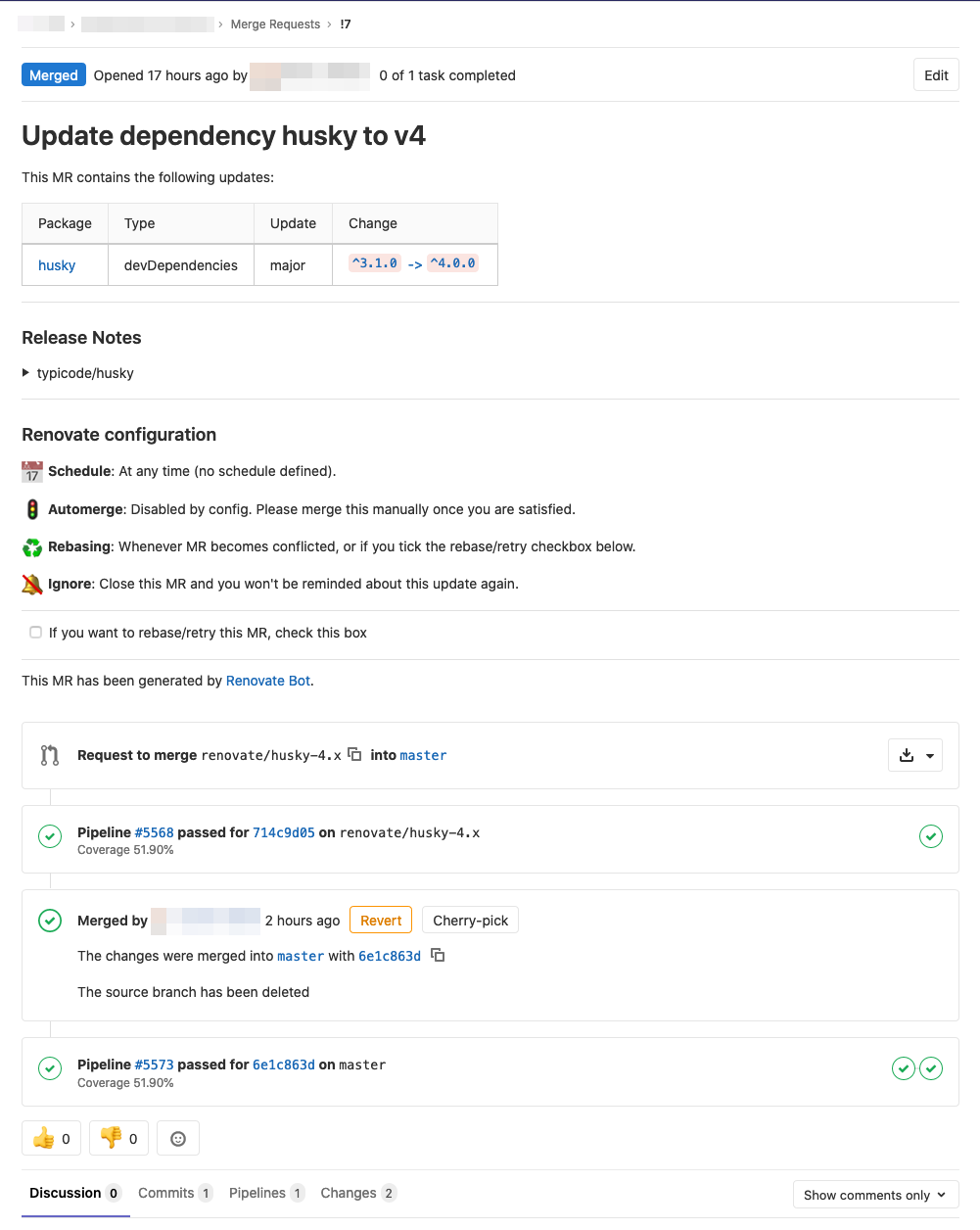
Automate your dependency management using update tool
Software often consists of not just your own code but also is dependent of third party libraries and other software which has their own update cycle and new versions are released now and then with fixes to vulnerabilities and with new features. Now the question is what is your dependency management strategy and how do…
-

Generating JWT and JWK for information exchange between services
Securely transmitting information between services and authorization can be achieved with using JSON Web Tokens. JWTs are an open, industry standard RFC 7519 method for representing claims securely between two parties. Here’s a short explanation and guide of what they are, their use and how to generate the needed things. “JSON Web Token (JWT) is…
-
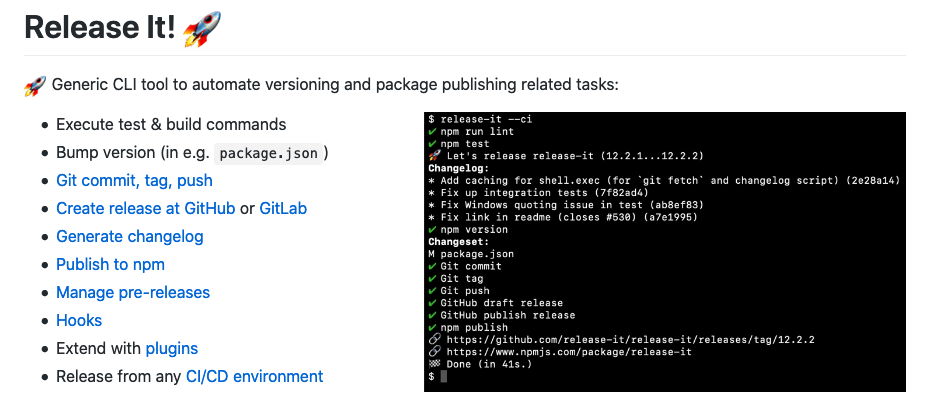
Automate versioning and changelog with release-it on GitLab CI/CD
It’s said that you should automate all the things and one of the things could be versioning your software. Incrementing the version number in your e.g. package.json is easy but it’s easier when you bundle it to your continuous integration and continuous deployment process. There are different tools you can use to achieve your needs…
-

Reset Hasura migrations and squash files
Using GraphQL for creating REST APIs is nowadays popular and there are different tools you can use. One of them is Hasura which is an open-source engine that gives you realtime GraphQL APIs on new or existing Postgres databases. Hasura is quite easy to work with but if your GraphQL schemas change a lot it creates…
-
Ignoring files and folders in Subversion with propset
Before committing code to the Subversion repository we always set the svn:ignore property on the directory to prevent some files and directories to be checked in. You would usually want to exclude the IDE project files and the target/ directory. It’s useful to put all the ignored files and directories into a file: .svnignore… Jatka…
-
Best Practices of forking git repository and continuing development
Sometimes there’s a need to fork a git repository and continue development with your own additions. It’s recommended to make pull request to upstream so that everyone could benefit of your changes but in some situations it’s not possible or feasible. When continuing development in forked repo there’s some questions which come to mind when…
-

Two days of React Finland 2018: Day two with React and React Native
React Finland 2018 conference was held last week and I had the opportunity to attend it and listen what’s hot in the React world. The conference started with workshops and after that there was two days of talks of React, React Native, React VR and all things that go with developing web applications with them.……
-

Two days of React Finland 2018: Day one topics of React
React Finland 2018 conference was held last week and I had the opportunity to attend it and listen what’s hot in the React world. The conference started with workshops and after that there was two days of talks of React, React Native, React VR and all things that go with developing web applications with them.……