Category: Development
-
Alpine Linux Dockerfile for PDF rendering: with Playwright and Puppeteer
Rendering PDF in software projects can be done with different ways and one of the easiest ways to do it is to craft HTML page and render it with Playwright or Puppeteer. Creating the HTML is the easiest part but if you’re not using the documented ways of using Playwright and Puppeteer and prefer to…
-

Notes of Best Practices for writing Playwright tests
Playwright “enables reliable end-to-end testing for modern web apps” and it has good documentation also for Best Practices which helps you to make sure you are writing tests that are more resilient. If you’ve done automated end-to-end tests with Cypress or other tool you probably already know the basics of how to construct robust tests…
-

Recap of 2023
Short recap of writings in 2023: 12 blog posts, 7 of them short notes. I managed to write couple of more detailed post and here’s my favorite ones of them with short recap. Notes from axe-con 2023: Building accessible experiences My notes from axe-con 2023 which is world’s largest digital accessibility conference.… Jatka lukemista →
-
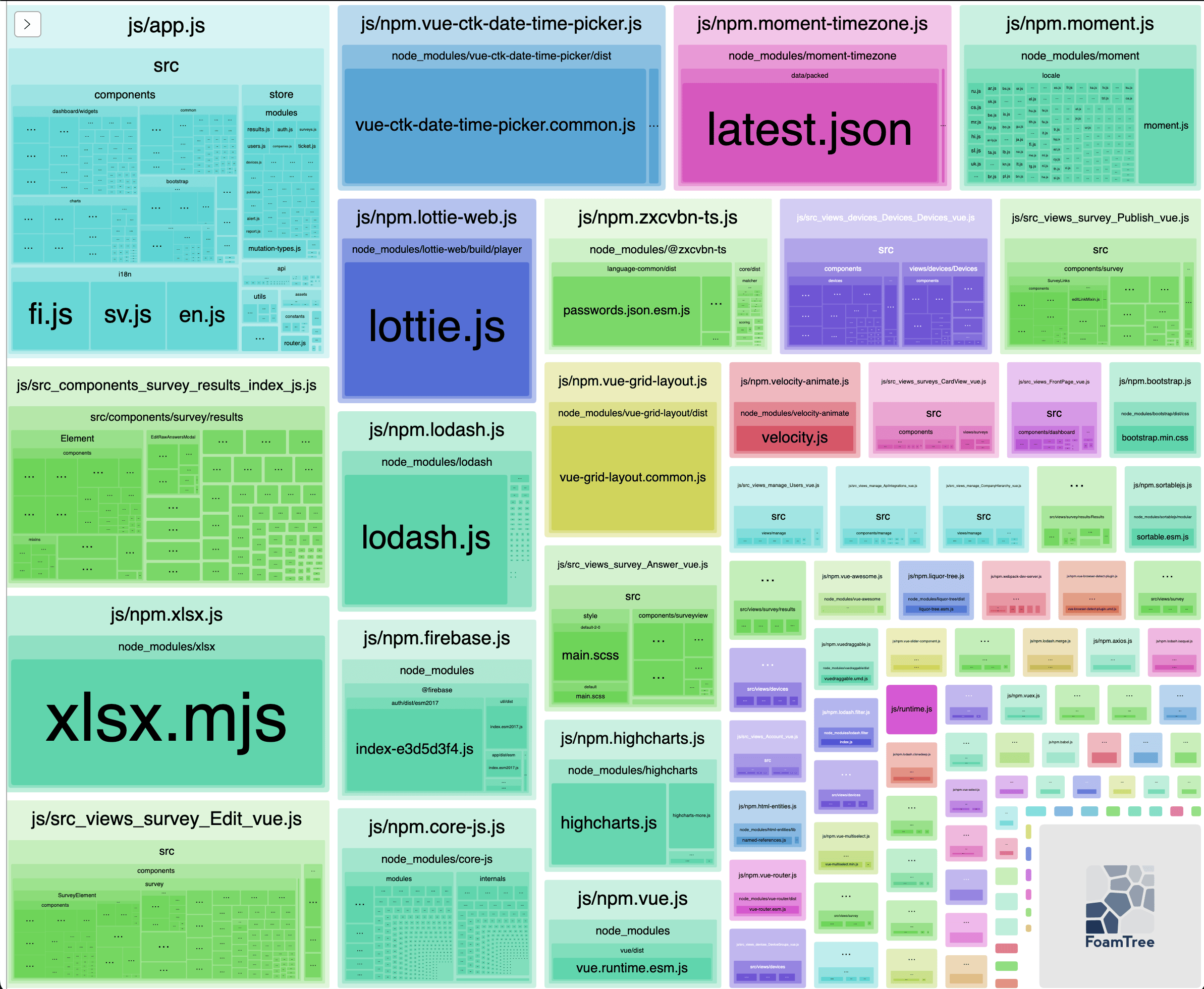
Analyzing Webpack bundles
Packaging your software can be done with different tools which bundles libraries and your code to groups of files (called chunks). Sometimes you might wonder why the chunks are so big and why some libraries are included although they are not used in some view (code splitting). There are different tools to analyze and visualize…
-

Developing with Accessibility in mind
Accessibility is often one part of the software development process which is “an additional” feature just like adding unit and integration tests later on which should be taken into account from the start. It’s not enough that it works or that it looks nice if the user doesn’t know how to use it or even…
-

Jailbreak detection with jail-monkey on React Native app
Mobile device operating systems often impose certain restrictions to what capabilities the user have on the device like which apps can be installed on the device and what access to information and data apps and user have on the device. The limitations can be bypassed with jailbreaking or rooting the device which might introduce security…
-
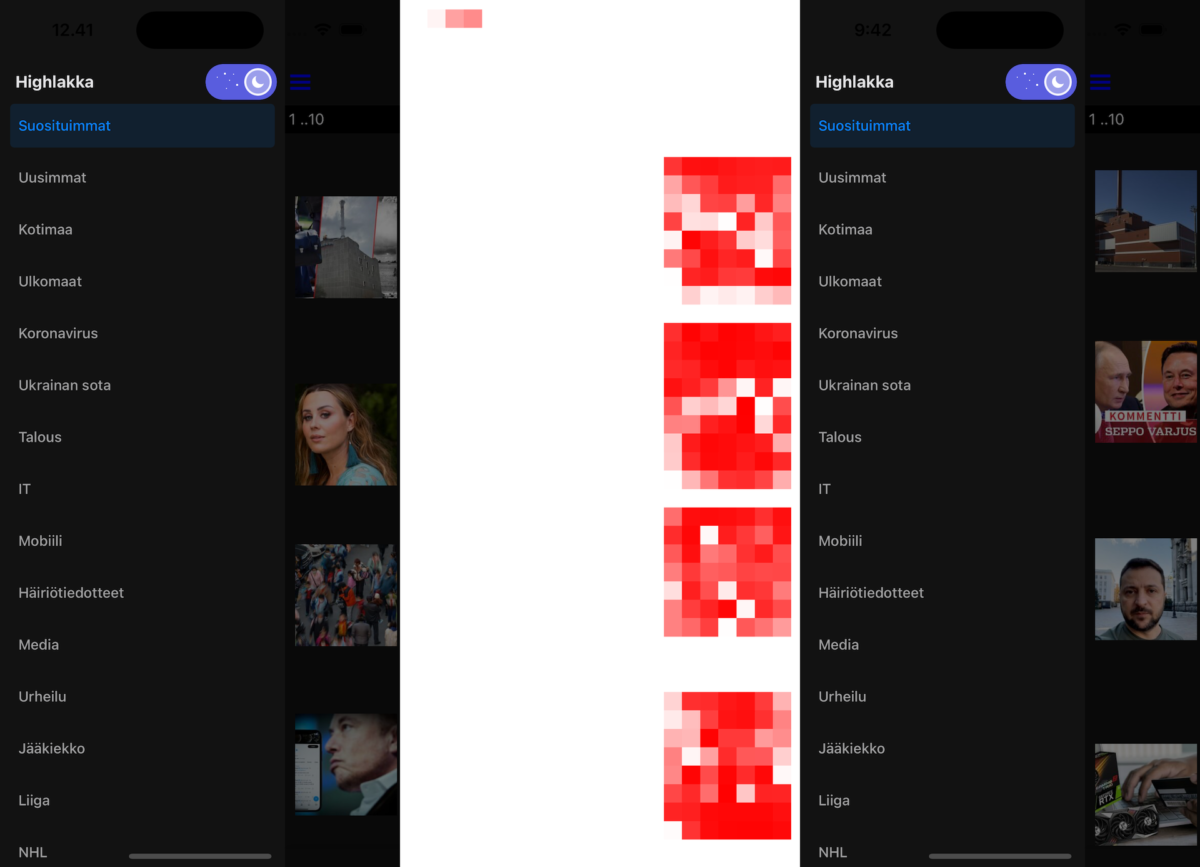
Automated End-to-End testing React Native apps with Detox
Everyone knows the importance of testing in software development projects so lets jump directly to the topic of how to use Detox for end-to-end testing React Native applications. It’s similar to how you would do end-to-end testing React applications with Cypress like I wrote previously. Testing React Native applications needs a bit more setup especially…
-
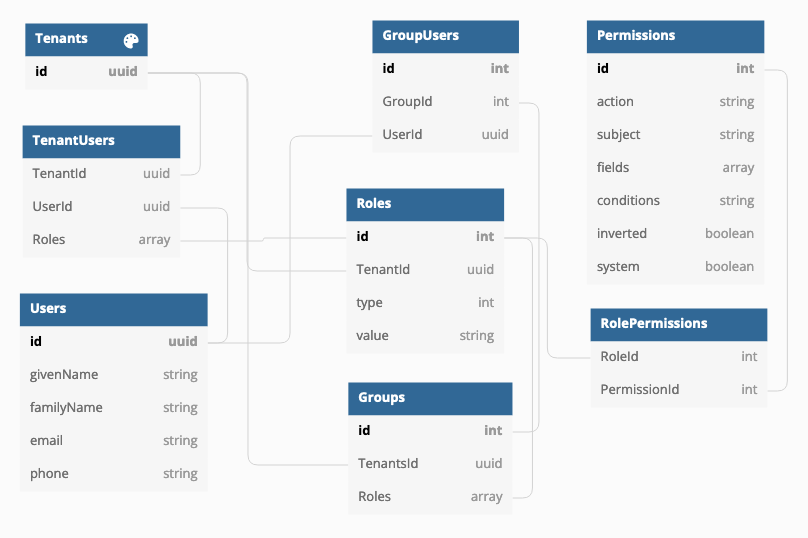
Using CASL and roles with persisted permissions
How do you implement user groups, roles and permissions in a multitenant environment where you have multiple organizations using the same application and each have own users and groups and roles? There are different approaches to the issue and one is to implement Attributes-based access control (ABAC) in addition with roles (RBAC).… Jatka lukemista →
-
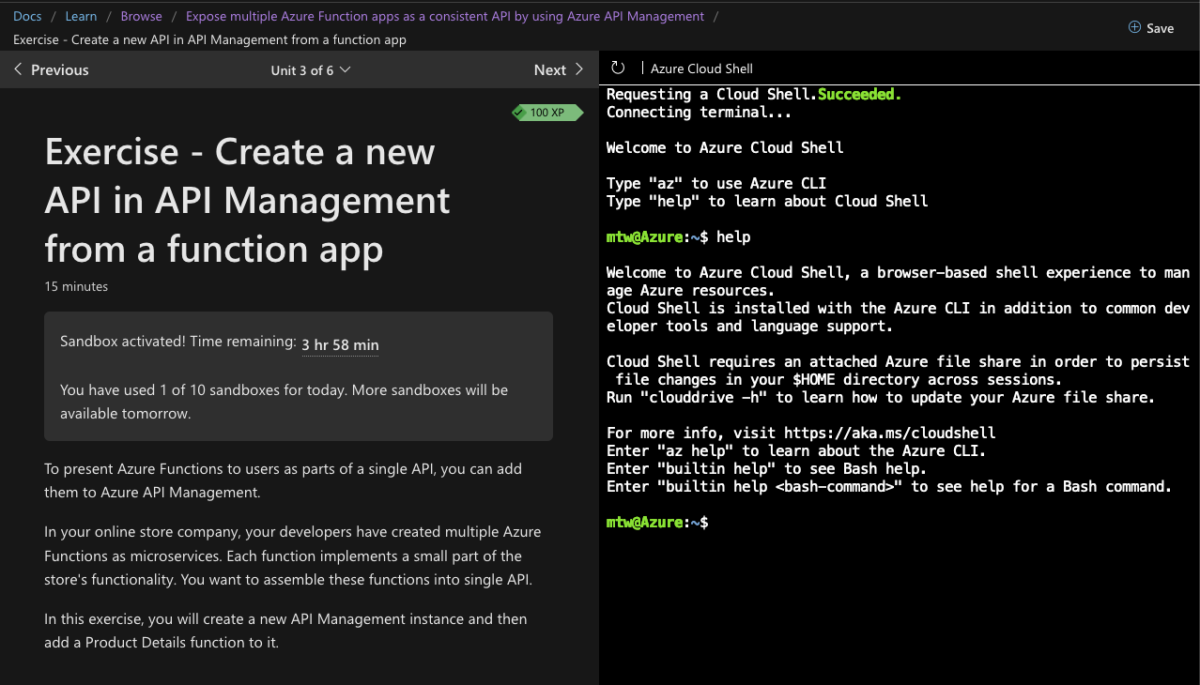
Notes from Microsoft Ignite Azure Developer Challenge
Microsoft Azure cloud computing service has grown steadily to challenge Amazon Web Services and Google Cloud Platform but until now I hadn’t had a change to try it and see how it compares to other platforms I’ve used. So when I came across the Microsoft Ignite: Cloud Skills Challenge November 2021 I was sold and took the opportunity to…
-

Create secure code with Secure Code Bootcamp
Software development contains many aspects which the developer has to take care and think about. One of them is information security and secure code which affects the product and its users. There are different ways to learn information security and how to create secure and quality code and this time I’ll shortly go through what…