-
Monthly notes 49
Working From Home edition. Issue 49, 27.3.2020 Conferences Now that COVID-19 has all of us in corontine and working from home, also the technology conferences have been moved to online and free. Here’s some. WFHConfWorking From Home Conf with talks from technology to projects, best practices, lessons learned and about working from home.… Jatka lukemista…
-
Using NGINX Ingress Controller on Google Kubernetes Engine
If you’ve used Kubernetes you might have come across Ingress which manages external access to services in a cluster, typically HTTP. When running with GKE the “default” is GLBC which is a “load balancer controller that manages external loadbalancers configured through the Kubernetes Ingress API”. It’s easy to use but doesn’t let you to to…
-
Keep Maven dependencies up to date
Software development projects come usually with lots of dependencies and keeping them up to date can be burdensome if done manually. Fortunately there are tools to help you. For Node.js projects there are e.g. npm-check and npm-check-updates and for Maven projects there are OWASP/Dependency-Check and Versions Maven plugins. Here’s a short introduction how to setup…
-
Monthly notes 48
This time monthly notes is for learning Node.js best practices and some interesting approaches for (Node.js) software architecture. Happy reading and be a better developer! Issue 48, 25.2.2020 Learning Docker and Node.js Best Practices talk at DockerCon 2019Slides and Examples . tl;dr; Use even numbered LTS releases; Don’t use :latest tag; Use Debian:slim/stretch or Alpine;…
-
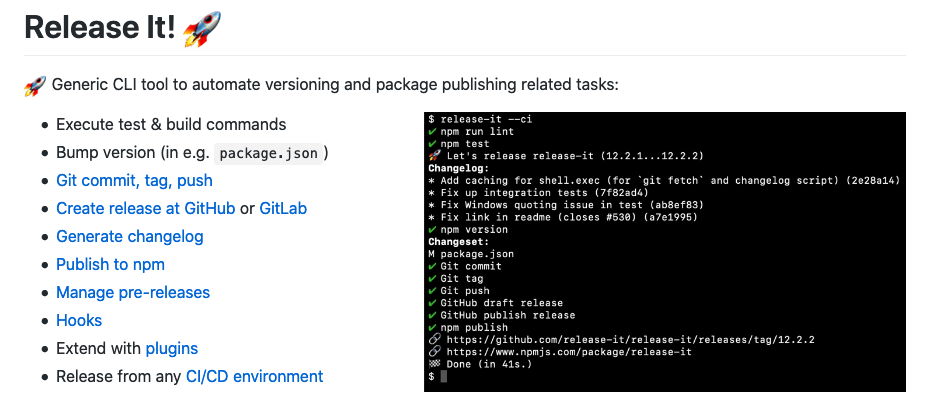
Automate versioning and changelog with release-it on GitLab CI/CD
It’s said that you should automate all the things and one of the things could be versioning your software. Incrementing the version number in your e.g. package.json is easy but it’s easier when you bundle it to your continuous integration and continuous deployment process. There are different tools you can use to achieve your needs…
-

Reset Hasura migrations and squash files
Using GraphQL for creating REST APIs is nowadays popular and there are different tools you can use. One of them is Hasura which is an open-source engine that gives you realtime GraphQL APIs on new or existing Postgres databases. Hasura is quite easy to work with but if your GraphQL schemas change a lot it creates…
-

Monthly notes 47
Issue 47: 30.1.2020 War Stories #Y2038 problem. “It’s *already here*. Fix your stuff.”In many systems time is represented as number of seconds passed since 00:00:00 UTC on 1 Jan 1970 and stored as signed 32-bit integer. Such implementations can’t encode times after 03:14:07 UTC on 19 January 2038. (from @walokra) Ops Lessons We All Learn…
-
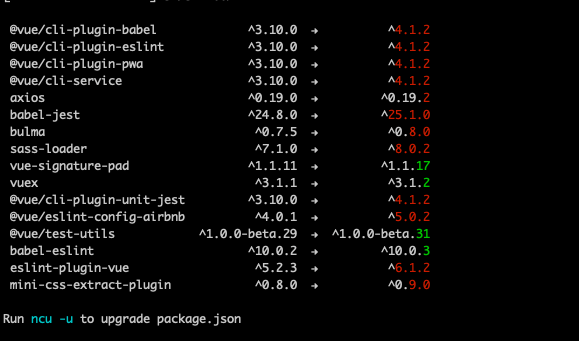
Tracking vulnerabilities and keeping Node.js packages up to date
Software evolves quickly and new versions of libraries are released but how do you keep track of updated dependencies and vulnerable libraries? Managing dependencies has always been somewhat a pain point but an important part of software development as it’s better to be tracking vulnerabilities and running fresh packages than being pwned.… Jatka lukemista →
-

Notes from security in the age of Docker & Kubernetes
Security is always the more obscure part of software development and while container runtimes provide good isolation from the host operating system when using Docker and running containers in Kubernetes, you should not assume to be free from exploits. Remember to use the best practices when you were not using containers.… Jatka lukemista →
-

Notes of Best Practices for writing Cypress tests
Cypress is a nice tool for end-to-end tests and it has good documentation also for Best Practices including “Cypress Best Practices” talk by Brian Mann at Assert(JS) 2018. Here are my notes from the talk combined with the Cypress documentation. This article assumes you know and have Cypress running.… Jatka lukemista →