-

Notes of Best Practices for writing Playwright tests
Playwright “enables reliable end-to-end testing for modern web apps” and it has good documentation also for Best Practices which helps you to make sure you are writing tests that are more resilient. If you’ve done automated end-to-end tests with Cypress or other tool you probably already know the basics of how to construct robust tests…
-
Short notes on tech 6/2024
DevOps Continuous Integration“An updated long-form post on continuous integration. Although not a new practice, it’s often misunderstood.” Embracing the Future: DevOps in 2024“Some predictions for Devops in 2024, focused on the continued move to the cloud, the importance of a security-first approach, AI/ML adoption and more.” Web Design and Accessibility 12 Modern CSS One-Line Upgrades“Sometimes,…
-

Recap of 2023
Short recap of writings in 2023: 12 blog posts, 7 of them short notes. I managed to write couple of more detailed post and here’s my favorite ones of them with short recap. Notes from axe-con 2023: Building accessible experiences My notes from axe-con 2023 which is world’s largest digital accessibility conference.… Jatka lukemista →
-
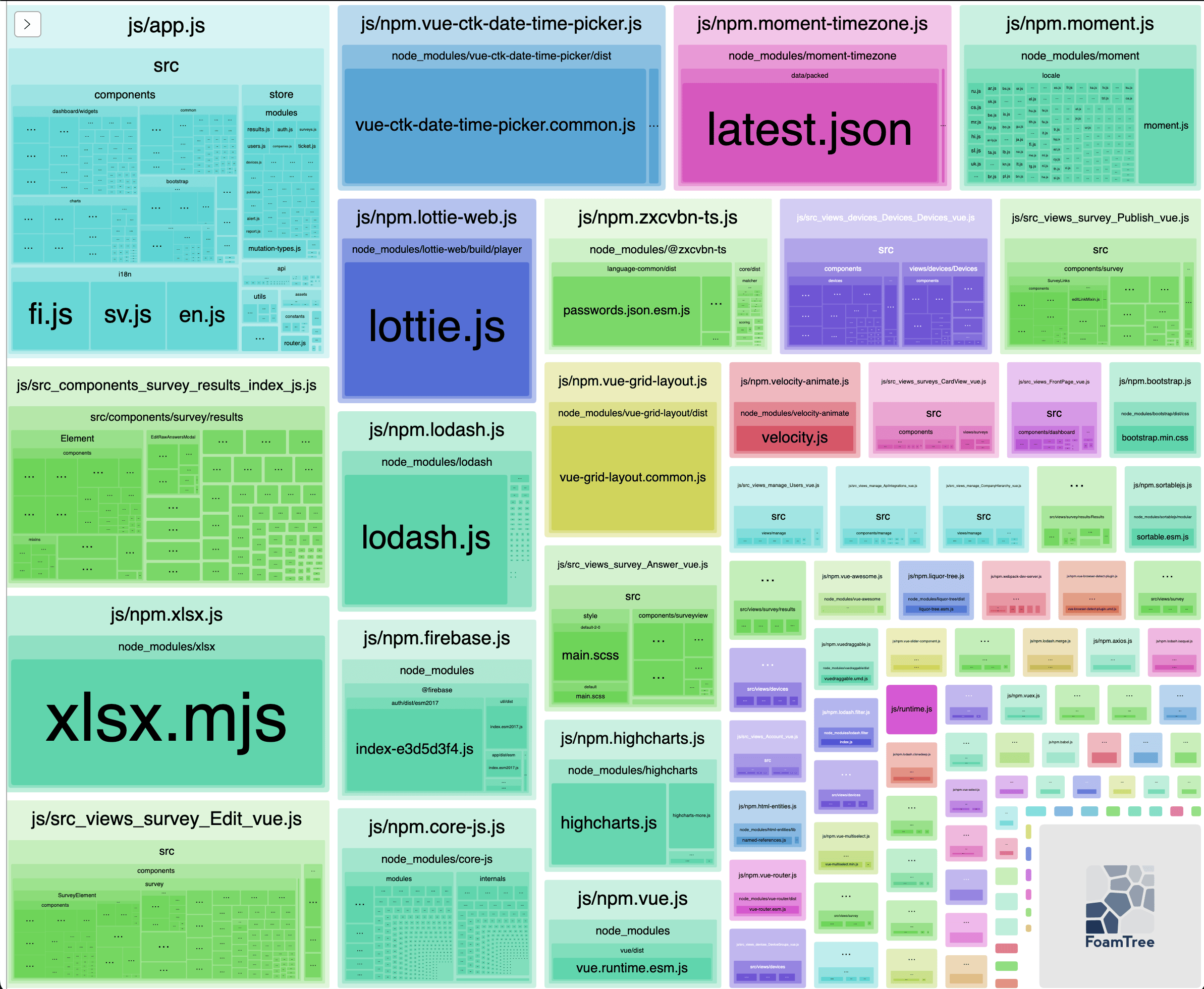
Analyzing Webpack bundles
Packaging your software can be done with different tools which bundles libraries and your code to groups of files (called chunks). Sometimes you might wonder why the chunks are so big and why some libraries are included although they are not used in some view (code splitting). There are different tools to analyze and visualize…
-
Short notes on tech 51/2023
This week short notes on tech is full of combination of software development (dev) and operations (ops). DevOps Spoofing Microsoft Entra ID Verified Publisher Status“It was possible to manipulate the consenting process of a legitimate verified publisher application to implant malicious unverified applications within a Microsoft Entra ID tenant.” (from CloudSecList) A Comprehensive Guide to…
-
Short notes on tech 46/2023
CSS Naming Variables In CSS“Jonathan Dallas shares some thoughts related to naming CSS Custom Properties.” Good points and reminders how to write effective CSS. (from CSS Weekly) Using CSS custom properties like this is a waste“Kevin Powell explores how you can make your code a lot more efficient by leveraging pseudo-private custom properties.”… Jatka lukemista…
-
Short notes on tech 40/2023
DevOps Source Code Management Platform Configuration Best Practices“Guide exploring the best practices for securing GitHub and GitLab, covering topics that include user authentication, access control, permissions, monitoring, and logging.” (from CloudSecList) GitHub Actions could be so much better“A good critical review of GitHub Actions, discussing some interesting security challenges, slow debugging cycles, the third party…
-

Developing with Accessibility in mind
Accessibility is often one part of the software development process which is “an additional” feature just like adding unit and integration tests later on which should be taken into account from the start. It’s not enough that it works or that it looks nice if the user doesn’t know how to use it or even…
-

Short notes on tech 37/2023
DevOps and security OWASP Kubernetes Top Ten“When adopting Kubernetes, we introduce new risks to our applications and infrastructure. The OWASP Kubernetes Top 10 is aimed at helping security practitioners, system administrators, and software developers prioritize risks around the Kubernetes ecosystem. The Top Ten is a prioritized list of these risks.… Jatka lukemista →
-
Short notes on tech 24/2023
Software design 365 Days of iOS Accessibility365DaysIOSAccessibility series that Daniel Devesa Derksen-Staats posts to Mastodon and Twitter. (from iOS Dev Weekly) DevOps Using Act to Run Github Actions Locally“Act could be the end of commit messages littering history that say, “Tweaked workflow file, again! Fingers crossed that it works this time!”… Jatka lukemista →